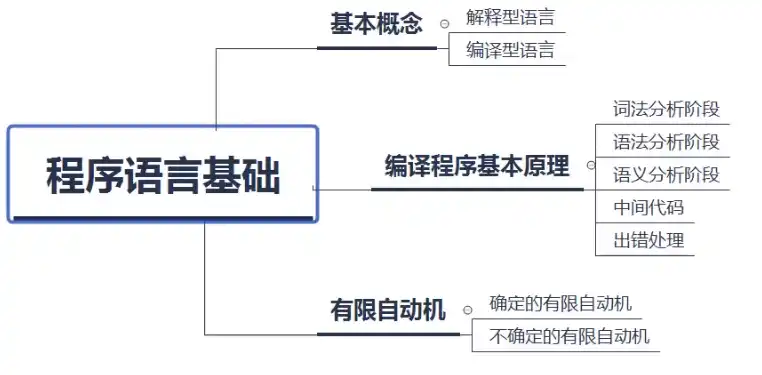
一 章节知识架构图
二 程序语言基本概念
解释型
① 没有中间代码生成与目标机器码代码
② 不产生目标程序
③ 运行效率低
编译型
① 保存机器码
② 生成目标程序
③ 运行效率高
三 编译程序基本原理
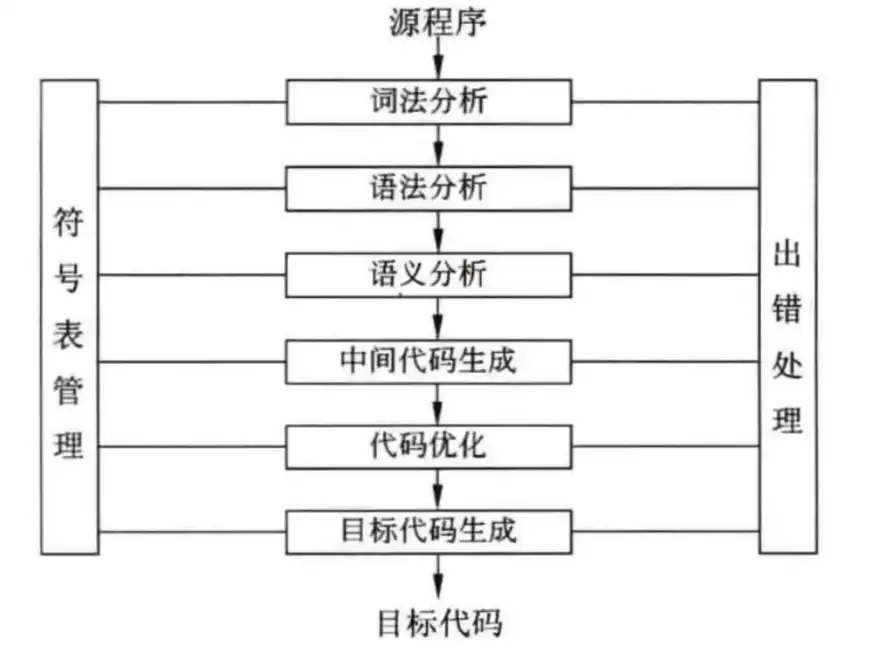
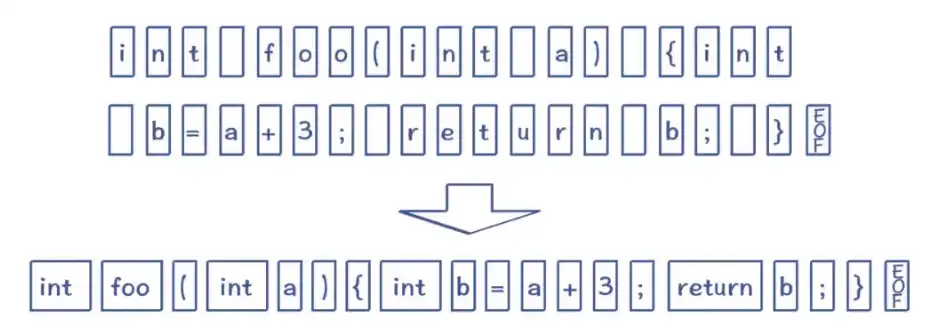
3.1 词法分析阶段
词法分析阶段:输入源程序,对构成源程序的字符串进行扫描和分解,识别出一个个的单词,删掉无用的信息,报告分析时的错误。
| |
3.2 语法分析阶段
语法分析阶段:语法分析器以单词符号作为输入,分析单词符号是否形成符合语法规则的语法单位,如表达式、赋值、循环等,按语法规则分析检查每条语句是否有正确的逻辑结构。
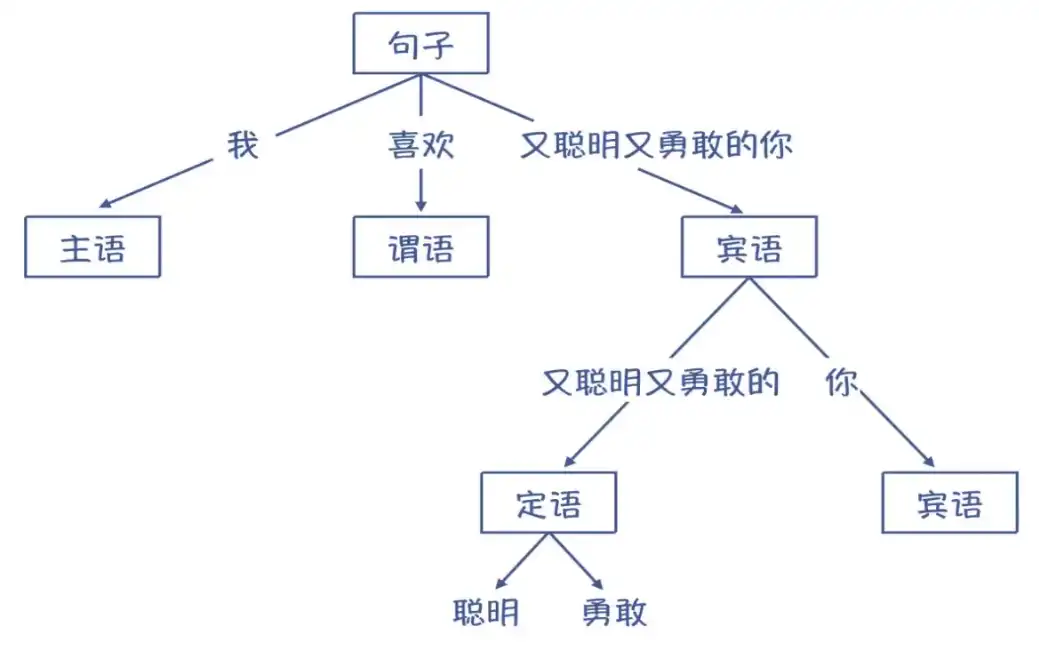
词法分析与语法分析本质上都是对源程序的结构进行分析。
3.3 语义分析阶段
语义分析阶段:主要检查源程序是否存在语义错误,并收集类型信息供后面的代码生成阶段使用,如:赋值语句的右端和左端的类型不匹配。表达式的除数是否为零等。
语义分析分为静态分析和动态分析两个部分。静态语义分析使用语法制导翻译。
3.4 中间代码生成
中间代码:不依赖具体计算机,表现形式如下:
(1)后缀式(逆波兰式)
(2)树型表示
(3)三元式:$X=(a+b)*(c+d)$
①(+,a,b) ②(+,c,d) ③(*, ①,②) ④(=, ③, x)
(4)四元式
3.5 出错处理
静态错误
编译时出现
- 语法错误
单词拼写错误、标点符号错误、表达式中缺少操作数、括号不匹配等有关语言结构上的错误。 - 静态语义错误
运算符与运算对象类型不合法。
动态错误
程序运行时出现
变量取 0 做除数、引用数组下标越界
真题示例 - 3.1:
以编译方式翻译 C/C++ 源程序的过程中,()阶段的主要任务是对各条语句的结构进行合法性分析。
A. 词法分析 B. 语义分析 C. 语法分析 D. 目标代码生成
真题示例 - 3.2:
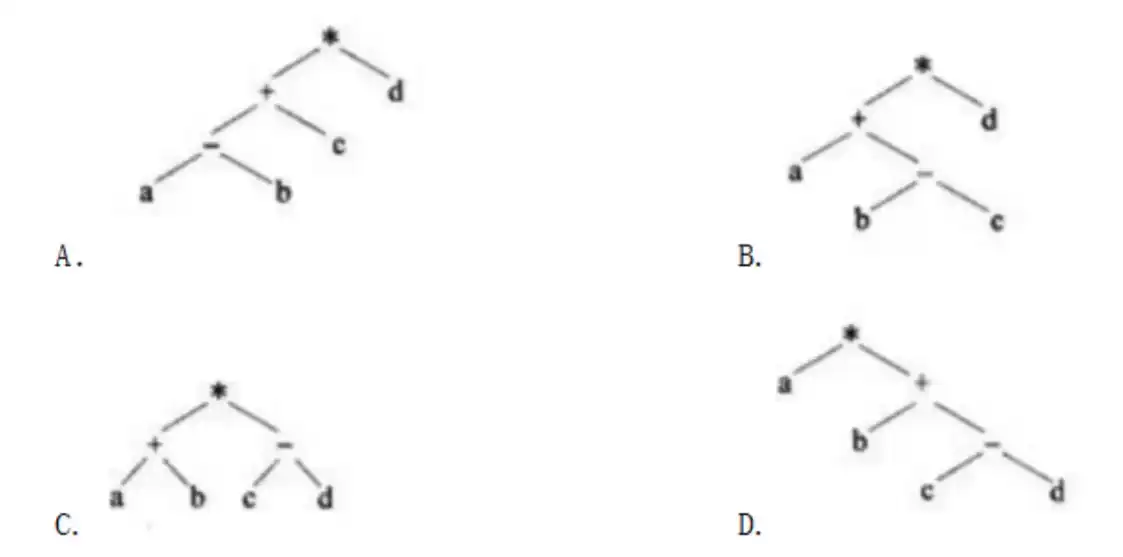
对于后缀表达式 $abc-+d*$(其中,$-$、$+$、* 表示二元算术运算减、加、乘),与该后缀式等价的语法树为()。
四 有限自动机

确定的有限自动机(DFA):该状态机在任何一个状态,基于输入的字符都能做成一个确定的状态转换。
不确定的有限自动机 (NFA):该状态机在任何一个状态,基于输入的字符都不能做成一个确定的状态转换。
这里分两种情况:
① 对于一个输入,它有两个状态可以转换;
② 存在 $\varepsilon$ 的情况,即没有任何字符输入的情况下,NFA 可以从一个状态迁移到另一个状态。
真题示例 - 4.1:
下图所示为一个非确定有限自动机(NFA),S0 为初态(S3 为终态)。该 NFA 识别的字符串为 ()。
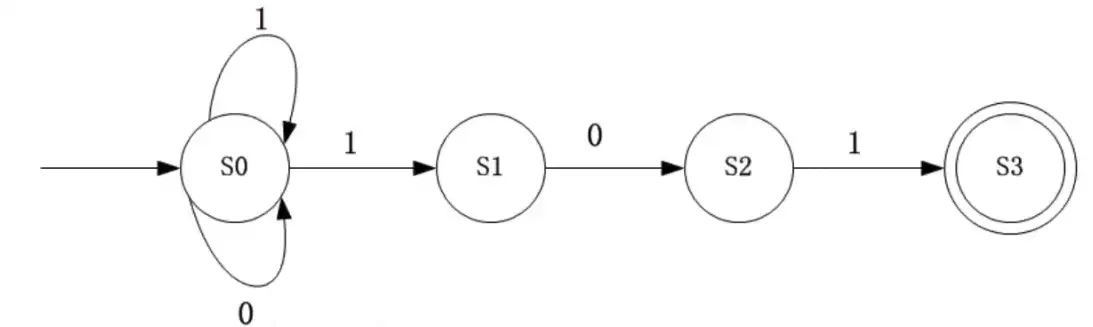
A. 不能包含连续的字符 “0”
B. 不能包含连续的字符 “1”
C. 必须以 “101” 开头
D. 必须以 “101” 结尾
真题示例 - 4.2:
某确定的有限自动机(DFA)的状态转换图如下图所示(A 是初态,D、E 是终态),则该 DFA 能识别()。
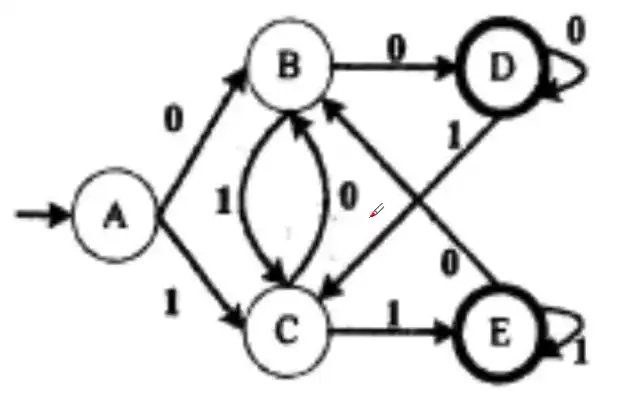
A. 00110 B. 10101 C. 11100 D. 11001
真题答案
| 题号 | 答案 |
|---|---|
| 3.1 | C |
| 3.2 | B |
| 4.1 | D |
| 4.2 | C |


感谢您的耐心阅读!来选个表情,或者留个评论吧!