一 章节知识架构图

二 线性结构
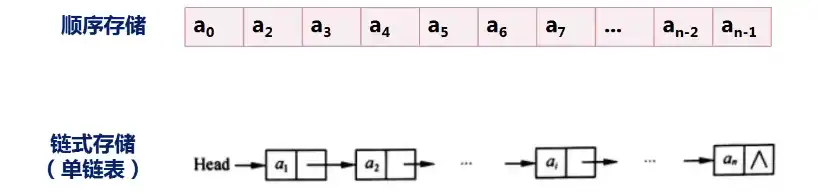
2.1 线性表
| 存储类型 | 特点 |
|---|---|
| 顺序存储 | 可以随机存取表中元素。插入和删除操作需要移动元素。移动元素的期望值:插入元素 n/2 个;删除元素 (n-1)/2 个 |
| 链式存储 | 链式存储结构有单链表、循环链表(循环单链表、循环双链表)等,其中单链表只能从头结点开始往后顺序遍历整个链表,而循环单链表可以从表中的任一结点开始遍历整个链表 |
真题示例 - 2.1
设有一个包含 n 个元素的有序线性表。在等概率情况下删除其中一个元素,若采用顺序存储结构,则平均需要移动()个元素;若采用单链表存储,则平均需要移动()个元素。
A. 1 B. (n-1)/2 C. Logn D. n
A. 0 B. 1 C. (n-1)/2 D. n/2
2.2 栈与队列

2.2.1 栈
栈的应用:表达式求值、括号匹配、递归
1)表达式求值:

2)括号匹配:()、[]、{}
- 当扫描到左括号时,则将其压入栈中;
- 当扫描到右括号时,从栈顶取出一个左括号。
- 如果能匹配,比如
(跟)匹配,[跟]匹配,{跟}匹配,则继续扫描剩下字符串。 - 如果扫描的过程中,遇到不能配对的右括号,或者栈中没有数据,则说明为非法格式。
- 当所有的括号都扫描完成之后,如果栈为空,则说明字符串为合法格式;否则说明有未匹配的左括号,为非法格式。
3)递归:
$4!=4 \times 3! = 3 \times 2! = 2 \times 1! = 1 \times 0! = 1 \times 1$
2.2.1.1 顺序存储结构
预先申请栈空间,栈满则元素不能入栈。

2.2.1.2 链式存储结构
用链表表示栈,用链表实现的栈称为链栈。由于栈中元素的插入和删除仅在栈顶一端进行,因此不必另外设置头指针,链表的头指针就是栈顶指针。

真题示例 - 2.2
栈的特点是后进先出,若用单链表作为栈的存储结构,并用头指针作为栈顶指针,则()。
A. 入栈和出栈操作都不需要遍历链表
B. 入栈和出栈操作都需要遍历链表
C. 入栈操作需要遍历链表而出栈操作不需要
D. 入栈操作不需要遍历链表而出栈操作需要
2.2.2 队列
队列的应用:打印队列。
2.2.2.1 顺序存储
用顺序存储线性表来表示队列,为了指明当前执行出队运算的队首位置,需要一个指针变量 head(称为头指针)。为了指明当前执行进队运算的队尾位置,也需要一个指针变量 tail(称为尾指针)。
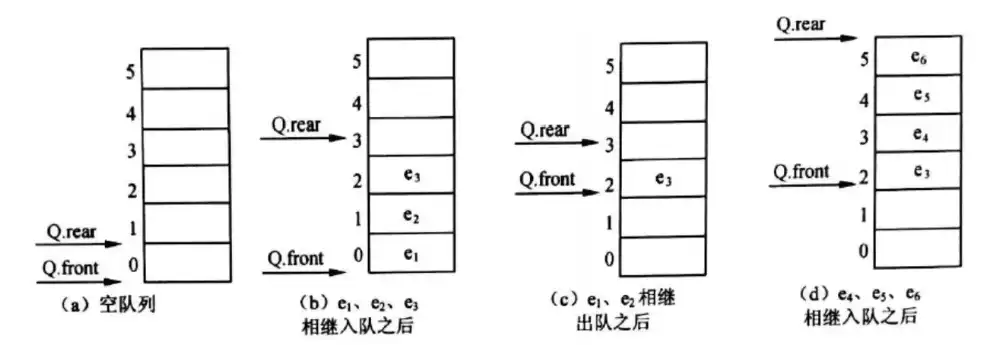
缺点:会造成空间的浪费。
2.2.2.2 链式存储
用链接存储线性表来实现队列,用链表实现的队列称为链接队列。

2.2.2.3 循环队列
循环队列解决顺序存储造成空间浪费的缺点。但是会存在无法判断空队列与队列满的情况(因为此时 front 和 rear 指针都指向相同位置)。解决办法:牺牲一个元素空间,空队列时 front = rear,队列满时 front = rear + 1.
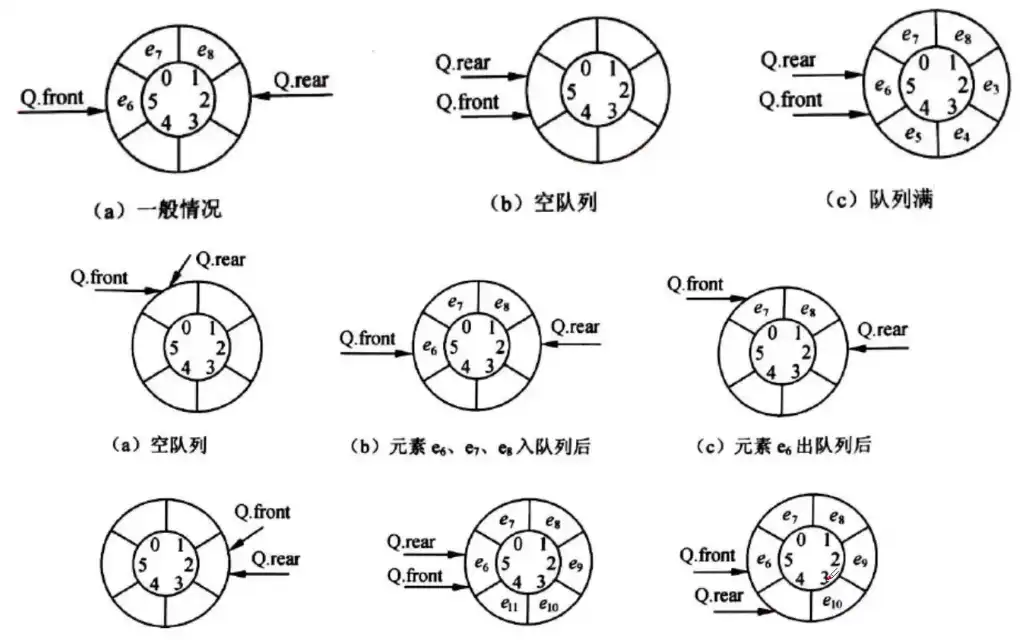
真题示例 - 2.3
某循环队列 Q 的定义中用 front 和 rear 两个整型域变量表示队列状态,其中 front 指示队头元素的位置,rear 指示队尾元素之后的位置(如下图所示,front 的值为 5、rear 的值为 1)。若队列容量 M (下面图中 M = 6),则计算队列长度的通式为()。
A. $\bf (Q.front - Q.rear)$
B. $\bf (Q.front - Q.rear + M) % M$
C. $\bf (Q.rear - Q.front)$
D. $\bf (Q.rear - Q.front + M) % M$
真题示例 - 2.4
对于一个长度为 n(n>1) 且元素互异的序列,令其所有元素依次通过一个初始为空的栈后,再通过一个初始为空的队列。假设队列和栈的容量都足够大,且只要栈非空就可以进行出栈操作,只要队列非空就可以进行出队操作,那么一下叙述中,正确的是()。
A. 出队序列和出栈序列一定互为逆序
B. 出队序列和出栈序列一定相同
C. 入栈序列和入队序列一定相同
D. 入栈序列与入队序列一定互为逆序
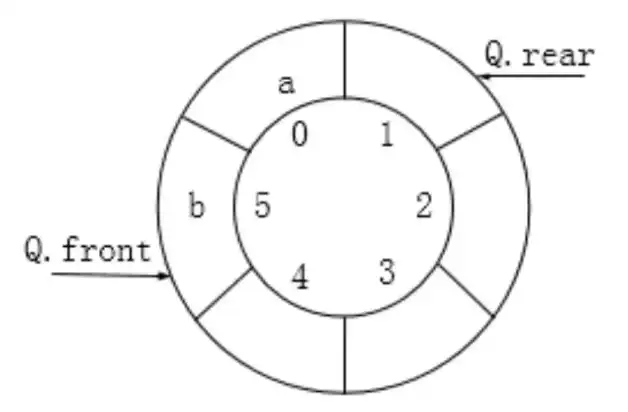
2.2.2.4 双端队列
某双端队列如下图所示,要求元素进出队列必须在同一端口,即从 A 端进入的元素必须从 A 端出、从 B 端进入的元素必须从 B 端出。

真题示例 - 2.5
双端队列是指在队列的两个端口都可以加入和删除元素,如下图所示,现在要求元素进队列和出队列必须在同一端口。即从 a 端进队的元素必须从 a 端出,从 b 端进队的元素必须从 b 端出。则对于四个元素的序列 a、b、c、d,若要求前两个元素 a、b 从 a 端口按次序全部进入队列。后两个元素 c、d 从 b 端口按次序全部进入队列,则不可能得到的出队序列是()。
A. d、a、b、c
B. d、c、b、a
C. b、a、d、c
D. b、d、c、a
2.3 串
串是仅由字符构成的有限序列,是一种线性表。一般记为 $s=‘a1a2 \cdots an’(n>0)$,其中 s 是串的名称,用单引号括起来的是字符序列是串值。串的基本概念:
- 空串:长度为零的串称为空串,空串不包含任何字符。
- 空格串:由一个或多个空格组成的串
- 子串:由串种任意长度的连续字符构成的序列称为子串。含有子串的串称为主串。空串是任意串的子串。
真题示例 - 2.6
设 S 是一个长度为 n 的非空字符串,其中的字符各不相同,则其互异的非平凡子串(非空且不同于 S 本身)个数为()。
A. $2n-1$ B. $n^2$ C. $n(n+1)/2$ D. $(n+2)(n-1)/2$
三 非线性结构
3.1 二维数组
$$ A_{m \times n}= \left[ \begin{matrix} a_{11} & a_{12} & a_{13} & \cdots & a_{1n} \\ a_{21} & a_{22} & a_{23} & \cdots & a_{2n} \\ \vdots & \vdots & \vdots & \ddots & \vdots \\ a_{m1} & a_{m2} & a_{m3} & \cdots & a_{mn} \end{matrix} \right] $$按行存储:
$$A_{m,n}=\big[[a_{11}a_{12} \cdots a_{1n}],[a_{21}a_{22} \cdots a_{2n}], \cdots,[a_{m1}a_{m2} \cdots a_{mn}]\big]$$按列存储:
$$A_{m,n}=\big[[a_{11}a_{21} \cdots a_{m1}],[a_{12}a_{22} \cdots a_{m2}], \cdots,[a_{1n}a_{2n} \cdots a_{mn}]\big]$$真题示例 - 3.1
某 n 阶矩阵 A 如下图所示,按行将元素存储在一堆数组 M 中,设 $a_{1,1}$ 存储在 M[1],那么 $a_{i,j}$(1 <= i, j <= n且 $a_{i,j}$ 位于三条对角线中),存储在 M()。
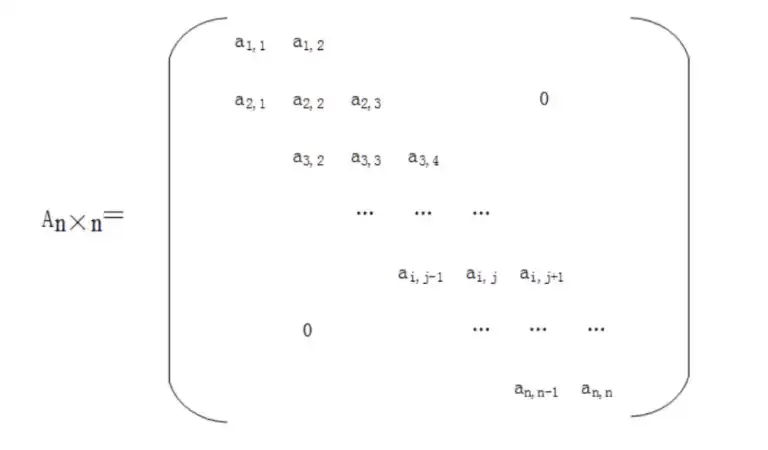
A. $i+2j$ B. $2i+j$ C. $i+2j-2$ D. $2i+j-2$
3.2 树
考试只考二叉树
- 父亲、孩子和兄弟
- 结点的度
- 叶子结点
- 内部结点
- 层次
- 树的高度
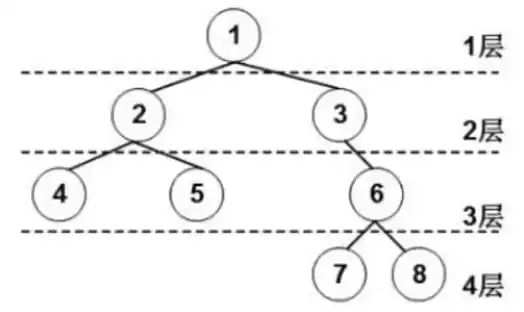
树的三种形式:

3.2.1 二叉树
- 在二叉树的第 i 层最多有 $2^{i-1}$ 个结点($i \geq 1$)
- 深度为 k 的二叉树最多有 $2^k-1$ 个结点($k \geq 1$)
- 对于任何一棵二叉树,如果其叶子结点数为 $N_0$,度为 2 的结点数为 $N_2$,则 $N_0=N_2+1$
- 具有 n 个结点的完全二叉树的深度为 $\lfloor \log_2n \rfloor +1$
如果 $i=1$,则结点 $i$ 无父结点,是二叉树的根
如果 $i>1$,则父结点是 $\lfloor i/2 \rfloor$
如果 $2i>n$,则结点 $i$ 为叶子结点,无左子结点,否则其左子结点是 $2i$
如果 $2i+1>n$,则结点 $i$ 无右子结点,否则,其右子结点是 $2i+1$
3.2.2 二叉树的遍历

| 遍历方式 | 结果 |
|---|---|
| 层次遍历 | 1、2、3、4、5、6、7、8 |
| 前序遍历 (根、左、右) | 1、2、4、5、7、8、3、6 |
| 中序遍历 (左、根、右) | 4、2、7、8、5、1、3、6 |
| 后序遍历 (左、右、根) | 4、8、7、5、2、6、3、1 |
真题示例 - 3.2
某二叉树的中序,先序遍历序列分别为 {20,30,10,50,40},{10,20,30,40,50} 则该二叉树的后序遍历序列为()。
A. 50,40,30,20,10
B. 30,20,10,50,40
C. 30,20,50,40,10
D. 20,30,10,40,50
真题示例 - 3.3
二叉树的高度是指其层数,空二叉树的高度为 0,仅有根结点的二叉树高度为 1。若某二叉树中共有 1024 个结点,则该二叉树的高度是整数区间的()中的任一值。
A. (10, 1024) B. [10, 1024]
C. (11, 1024) B. [11, 1024]
3.2.3 二叉树的存储
3.2.3.1 顺序存储
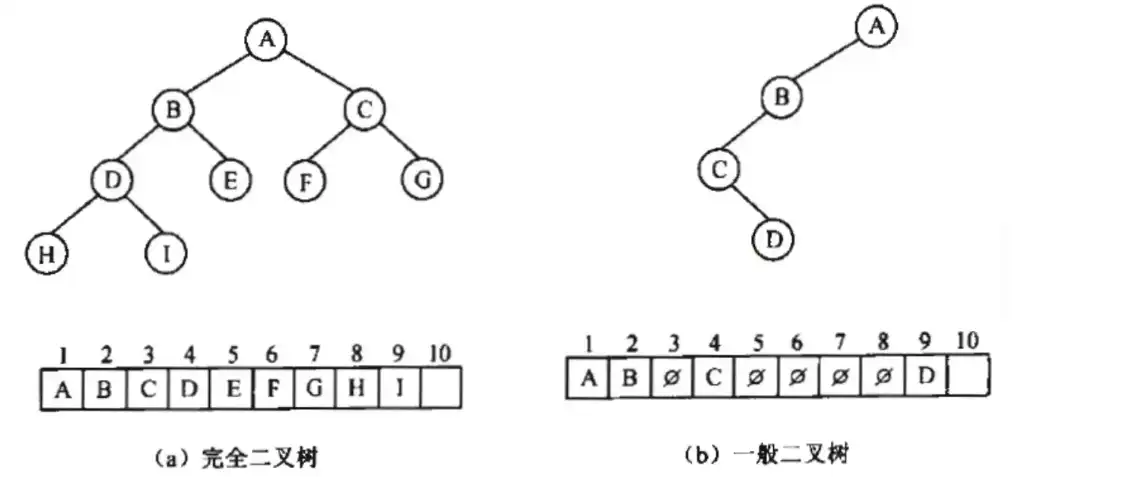
真题示例 - 3.4
对下面的二叉树进行顺序存储(用数组 MEM 表示),已知结点 A、B、C 在 MEM 中对应元素的下标分别为 1、2、3,那么结点 D、E、F 对应的数组元素下标为()。

A. 4、5、6 B. 4、7、10 C. 6、7、8 D. 6、7、14
3.2.3.2 链式存储

3.2.4 二叉查找树
二叉排序树又称为二叉查找树,其定义为二叉排序树或者是一棵空二叉树,或者是具有如下性质的二叉树:
(1)若它的左子树非空,则左子树上所有结点的值均小于根结点。
(2)若它的右子树非空,则右子树上所有结点的值均大于根结点。
(3)左、右子树本身右各是一个二叉排序树。

如果中序遍历二叉排序树,就能得到一个排好序的结点序列。
3.2.5 哈夫曼树
给定 N 个权值作为 N 个叶子结点,构造一棵二叉树,若该树的带权路径长度达到最小,称这样的二叉树为最优二叉树,也称为哈夫曼树(Huffman Tree)。哈夫曼树是带权路径长度最短的树,权值较大的结点离根较近。
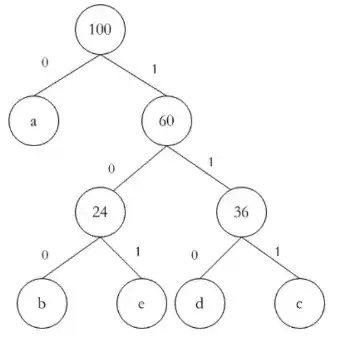
真题示例 - 3.5
已知一个文件中出现的各字符及其对应的频率如下表所示。采用 Huffman 编码,则该文件中字符 a 和 c 的码长分别为()。若采用 Huffman 编码,则字符序列 110001001101 的编码应为()。
| 字符 | a | b | c | d | e | f |
|---|---|---|---|---|---|---|
| 频率 (%) | 45 | 13 | 12 | 16 | 9 | 5 |
A. 1 和 3 B. 1 和 4 C. 3 和 3 D. 3 和 4
A. face B. bace C. acde D. fade
3.3 图
图 G 由两个集合 V 和 E 组成,记为 $G = (V,E)$,其中 V 是顶点的有穷非空集合,E 是 V 中顶点偶对(称为边)的有穷集合。通常,也将图 G 的顶点集和边集分别记为 V(G) 和 E(G)。E(G) 可以是空集。若 E(G) 为空,则图 G 只有顶点而没有边。

3.3.1 完全图
若一个无向图具有 n 个顶点,而每个顶点与其他 n-1 个顶点之间都有边,则称为无向完全图。无向完全图共有 $\bf \frac{n(n-1)}{2}$ 条边。
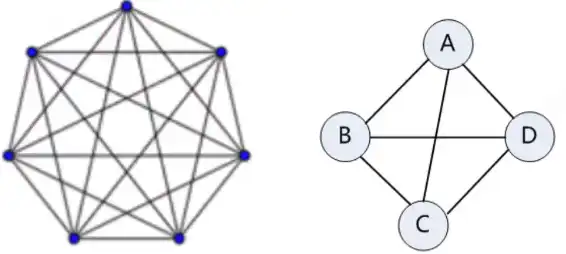
有 n 个顶点的有向完全图中弧的数目为 $n(n-1)$,即任意两个不同顶点之间都有方向相反的两个弧存在。
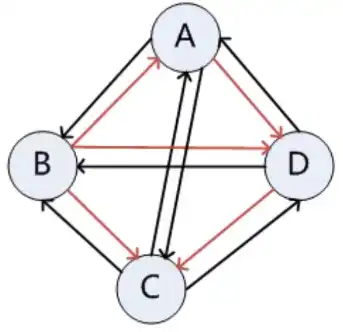
3.3.2 连通图
在无向图 G 中,若从顶点 $V_i$ 到顶点 $V_j$ 有路径,则称顶点 $V_i$ 和顶点 $V_j$ 是连通的。如果无向图 G 中任意两个顶点都是连通的,则称其为连通图。
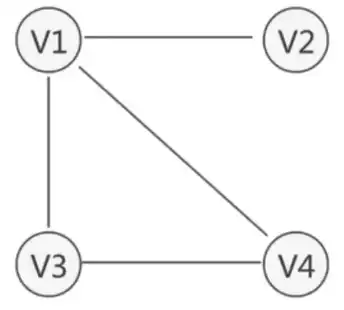
3.3.3 强连通图
有向图中,若任意两个顶点 $V_i$ 和 $V_j$,满足从 $V_i$ 到 $V_j$ 以及从 $V_j$ 到 $V_i$ 都连通,也就是都含有至少一条通路,则称为强连通图。有向图中的极大连通图子图称为有向图的强连通分量。

3.3.4 图的存储结构
3.3.4.1 邻接矩阵
有向图的邻接矩阵不一定对称。
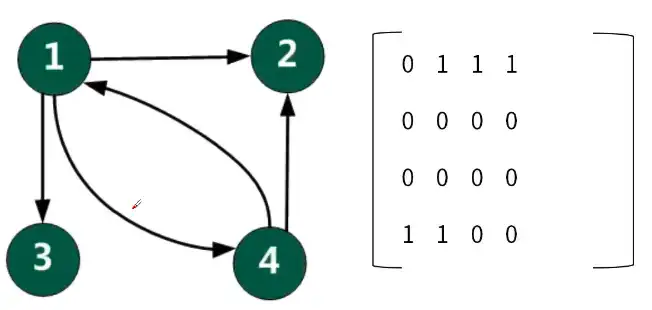
无向图的邻接矩阵是对称的。

3.3.4.2 邻接表
在图的邻接表中,为图的每个顶点建立一个链表,且第 i 个链表中的结点代表与顶点 i 相关联的一条边或由顶点 i 出发的一条弧。有 n 个顶点的图,需要用 n 个链表表示,这 n 个链表的头指针通常由顺序线性表存储。
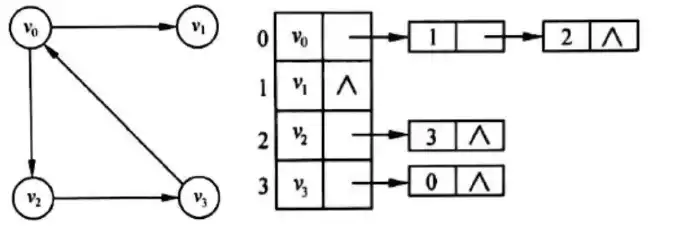
3.3.5 图的遍历
图的遍历是指从某个顶点出发,沿着某条搜索路径对图中的所有顶点进行访问且只访问一次的过程。

| 方法 | 示例 | 特征 |
|---|---|---|
| 深度优先 DFS | V1,V2 V4,V8 V5,V3 V6,V7 | 相当于树的前序遍历。邻接矩阵表示的时间复杂度 $O(n^2)$,邻接表表示的实际复杂度是 $O(n+e)$ |
| 广度优先 BFS | V1,V2 V3,V4 V5,V6 V7,V8 | 相当于树的层次遍历。时间复杂度同上 |
真题示例 - 3.6
图 G 的邻接矩阵如下图所示(顶点依次表示为 v0, v1, v2, v3, v4, v5),G 是()。对 G 进行广度优先遍历(从 v0 开始),可能的遍历序列为()。
$$ \left[ \begin{matrix} \infty & 18 & 17 & \infty & \infty & \infty \\ \infty & \infty & \infty & 20 & 16 & \infty \\ \infty & 19 & \infty & 23 & \infty & \infty \\ \infty & \infty & \infty & \infty & \infty & 15 \\ \infty & \infty & \infty & \infty & \infty & 12 \\ \infty & \infty & \infty & \infty & \infty & \infty \\ \end{matrix} \right] $$A. 无向图 B. 有向图 C. 完全图 D. 强连通图
A. v0、v1、v2、v3、v4、v5
B. v0、v2、v4、v5、v1、v3
C. v0、v1、v3、v5、v2、v4
D. v0、v2、v4、v3、v5、v1
真题示例 - 3.7
对于如下所示的有向图,其邻接矩阵是一个()的矩阵,采用邻接链表存储时顶点的表结点个数为 2,顶点 5 的表结点个数为 0,顶点 2 和 3 的表结点个数分别为()。
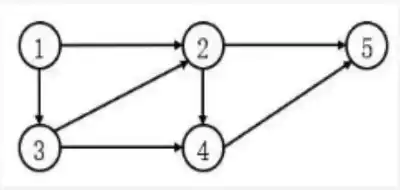
A. 5*5 B. 5*7 C. 7*5 D. 7*7
A. 2.1 B. 2.2 C. 3.4 D. 4.3
四 数据运算
4.1 时间复杂度
4.1.1 $O(1)$
| |
以上三条单个语句的频度均为 1,是一个常数阶,记作 $T(n)=O(1)$。此算法的执行时间不随着问题规模 n 的增加而增长,即使算法中有上千条语句,其执行时间也不过是一个较大的常数。此算法的时间复杂度是 $O(1)$。
4.1.2 $O(n)$
| |
一共算了 n 次加法,那么就说这个时间复杂度是 $O(n)$。比如,某个计算共计算了 $2n+1$ 次,那么这个时间复杂度也是 $O(n)$
4.1.3 $O(n^2)$
| |
4.1.4 $\log_2(n)$
二分查找每次排除掉一半不适合值,所以对于 n 个元素的情况:
- 一次二分剩下:$n/2$
- 两次二分剩下:$n/2/2 = n/4$
- 三次二分剩下:$n/4/2 = n/8$
- m 次二分剩下:$n/(2^m)$
在最坏情况下是在排除到只剩下最后一个值之后得到结果,所以为 $\frac{n}{(2^m)}=1 \Rightarrow n=2^m$,所以时间复杂度为 $\log_2(n)$
4.2 查找算法
4.2.1 顺序查找
将待查的元素从头到尾与表中元素进行比较,如果存在,则返回成功;否则,查找失败。此方法效率不高,平均查找长度 $\textcolor{red}{(n+1)/2}$(设置监视哨)
4.2.2 二分查找
【例题】请给出在含有 12 个元素的有序表 {1,4,10,16,17,18,23,29,33,40,50,51} 中二分查找关键字 17 的过程。
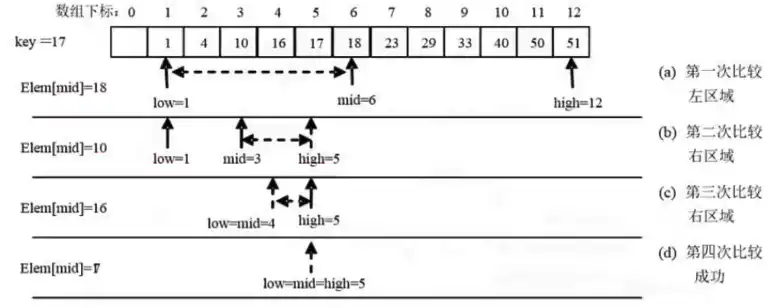
4.2.3 哈希查找
哈希表 hashtable 通过一个已记录的关键字为自变量的函数(哈希函数)得到该记录的存储地址,所以在哈希表中进行查找操作时,需用同一个哈希函数计算得到待查记录的存储地址,然后到相应的存储单元去获取有关信息再判定查找是否成功。
冲突的解决方式:随机探测再散列、线性探测。
【例题】设关键码序列为”47,34,13,12,52,38,33,27,3”,哈希表表长为 11,哈希函数为 Hash(key)=key mod 11,则
Hash(47) = 47 MOD 11 = 3, Hash(34) = 34 MOD 11 = 1,
Hash(13) = 13 MOD 11 = 2, Hash(12) = 12 MOD 11 = 1,
Hash(52) = 52 MOD 11 = 8, Hash(38) = 38 MOD 11 = 5,
Hash(33) = 33 MOD 11 = 0, Hash(27) = 27 MOD 11 = 5,
Hash(3) = 3 MOD 11 = 3
使用线性探测法解决冲突构造的哈希表如下:
| 哈希地址 | 0 | 1 | 2 | 3 | 4 | 5 | 6 | 7 | 8 | 9 | 10 |
|---|---|---|---|---|---|---|---|---|---|---|---|
| 关键字 | 33 | 34 | 13 | 47 | 12 | 38 | 27 | 3 | 52 |
使用链地址法构造的哈希表如图所示:
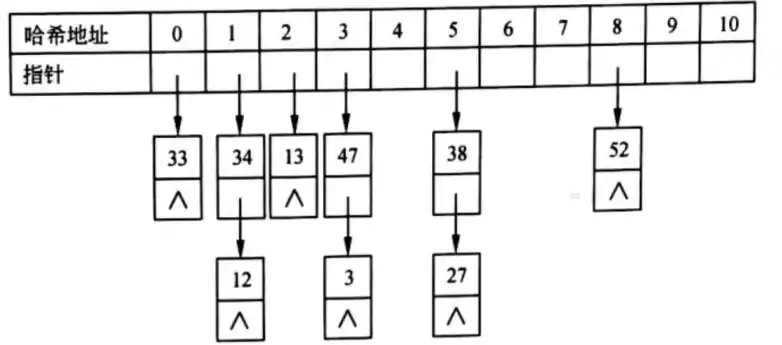
上图所示的哈希表中进行成功查找的平均查找长度 ASL 为 $6 \times 1 + 3 \times 2)/9 \approx 1.34$
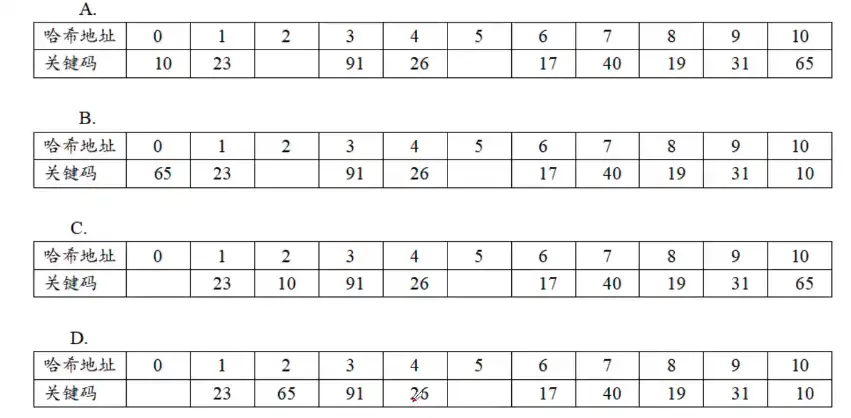
真题示例 - 4.1
设散列函数为 $H(key)= key \mod 11$ 对于关键字序列(23,40,91,17,19,10,31,65,26),用线性探测法解决冲突构造的哈希表为()。
4.3 排序算法
| 排序方法 | 时间复杂度 最好 | 时间复杂度 最坏 | 时间复杂度 平均 | 稳定性 |
|---|---|---|---|---|
| 直接插入 | $O(n) $ | $O(n^2) $ | $O(n^2) $ | 稳定 |
| 简单选择 | $O(n^2) $ | $O(n^2) $ | $O(n^2) $ | 不稳定 |
| 冒泡排序 | $O(n) $ | $O(n^2) $ | $O(n^2) $ | 稳定 |
| 希尔排序 | $O(n) $ | $O(n^{1.3}) $ | $O(n^{1.3}) $ | 不稳定 |
| 快速排序 | $O(n^2) $ | $O(n\log_2{n}) $ | $O(n\log_2{n}) $ | 不稳定 |
| 堆排序 | $O(n\log_2{n}) $ | $O(n\log_2{n}) $ | $O(n\log_2{n}) $ | 不稳定 |
| 归并排序 | $O(n\log_2{n}) $ | $O(n\log_2{n}) $ | $O(n\log_2{n}) $ | 稳定 |
4.3.1 直接插入排序
4.3.2 冒泡排序
【例题】排序数组:int[] arr = {6,3,8,2,9,1}
第一趟排序:
- 第一次排序:6 和 3 比较,6 大于 3,交换位置:3 6 8 2 9 1
- 第二次排序,6 和 8 比较,6 小于 8,不交换位置:3 6 8 2 9 1
- 第三次排序:8 和 2 比较,8 大于 2,交换位置:3 6 2 8 9 1
- 第四次排序:8 和 9 比较,8 小于 9,不交换位置:3 6 2 8 9 1
- 第五次排序:9 和 1 比较,9 大于 1,交换位置:3 6 3 8 1 9
第一趟总共进行了 5 次比较,排序结果:3 6 2 8 1 9
第二趟排序:
- 第一次排序:3 和 6 比较,3 小于 6,不交换位置:3 6 2 8 1 9
- 第二次排序:6 和 2 比较,6 大于 2,交换位置:3 2 6 8 1 9
- 第三次排序:6 和 8 比较,6 大于 8,不交换位置:3 2 6 8 1 9
- 第四次排序:8 和 1 比较,8 大于 1,交换位置:3 2 6 1 8 9
第二趟总共进行了 4 次比较,排序结果:3 2 6 1 8 9
第三趟排序:
- 第一次排序:3 和 2 比较,3 大于 2,交换位置:2 3 6 1 8 9
- 第二次排序:3 和 6 比较,3 小于 6,不交换位置:2 3 6 1 8 9
- 第三次排序:6 和 1 比较,6 大于 1,交换位置:2 3 1 6 8 9
第三趟总共进行了 3 次排序,排序结果:2 3 1 6 8 9
第四趟排序:
- 第一次排序:2 和 3 比较,2 小于 3,不交换位置:2 3 1 6 8 9
- 第二次排序:3 和 1 比较,3 大于 1,交换位置:2 1 3 6 8 9
第四趟总共进行了 2 次排序,排序结果:2 1 3 6 8 9
第五趟排序:
- 第一次排序:2 和 1 比较,2 大于 1,交换位置:1 2 3 6 8 9
第五趟总共进行了 1 次排序,排序结果:1 2 3 6 8 9
最终结果:1 2 3 6 8 9
4.3.3 简单选择排序
初始关键字:【8,5,2,6,9,3,1,4,0,7】
第一趟排序后:0,【5,2,6,9,3,1,4,8,7】
第二趟排序后:0,1,【2,6,9,3,5,4,8,7】
第三趟排序后:0,1,2,【6,9,3,5,4,8,7】
第四趟排序后:0,1,2,3,【9,6,5,4,8,7】
第五趟排序后:0,1,2,3,4,【6,5,9,8,7】
第六躺排序后:0,1,2,3,4,5,【6,9,8,7】
第七趟排序后:0,1,2,3,4,5,6,【9,8,7】
第八趟排序后:0,1,2,3,4,5,6,7,【8,9】
第九趟排序后:0,1,2,3,4,5,6,7,8,【9】
结果:【0,1,2,3,4,5,6,7,8,9】
4.3.4 希尔排序
先将整个待排元素序列分割成若干个子序列(由相隔某个“增量”的元素组成的)分别进行直接插入排序,然后依次缩减增量再进行排序,待整个序列中的元素基本有序(增量足够小)时,再对全体元素进行一次直接插入排序。因为直接插入排序再元素基本有序的情况下(接近最好情况),效率是最高的。
先取一个小于 n 的整数 d1,作为第一个增量,把文件的全部记录分成 d1 个组,即将所有距离为 d1 倍数序号的记录放在同一个组中,在组内进行直接插入排序;然后取第二个增量 d2 < d1,重复上述步骤,依次类推,直到所取的增量 di = 1,即将所有记录放在同一组进行直接插入排序。
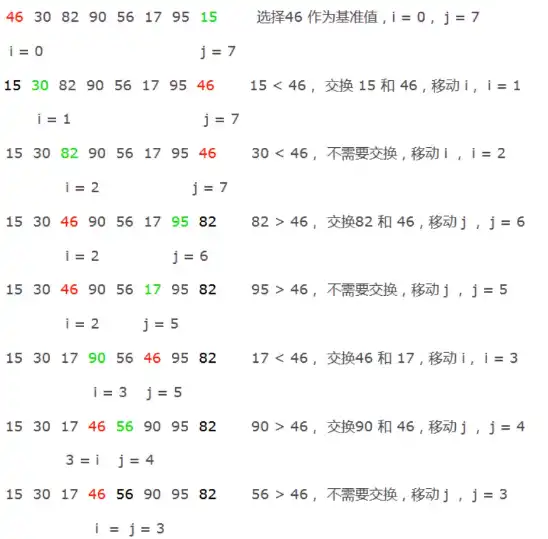
4.3.5 快速排序
初始状态:46 30 82 90 56 17 95 15
4.3.6 堆排序
对于 n 个元素的关键字序列 ${K_1,K_2, \cdots, K_n}$,当且仅当满足下列关系时称其为堆,其中 $2i$ 和 $2i+1$ 应不大于 n。
$$ \begin{cases} K_i \leq K_{2i} \\ K_i \leq K_{2i+1} \end{cases} 或 \begin{cases} K_i \geq K_{2i} \\ K_i \geq K_{2i+1} \end{cases} $$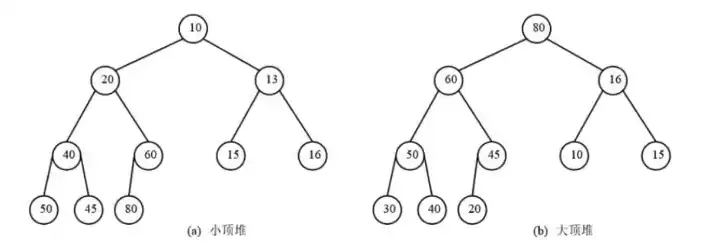
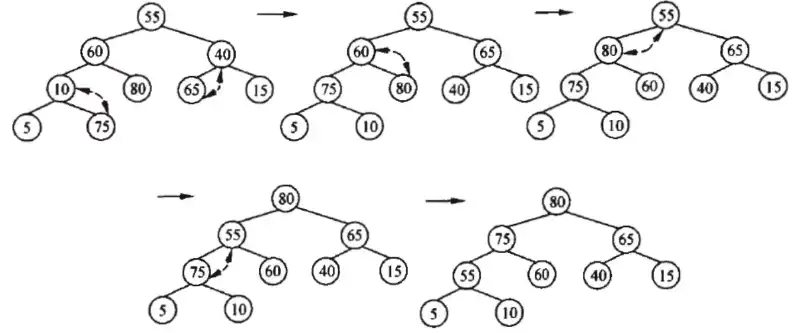
为序列(55,60,40,10,80,65,15,5,75)建立初始大根堆的过程如图 3-56 所示,调整为新堆的过程如图 3-57 所示。
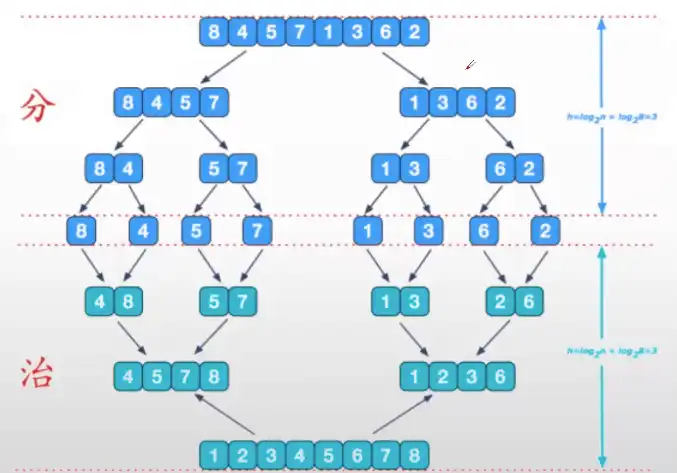
4.3.7 归并排序
(1)分解。将 n 个元素分层各含 n/2 个元素的子序列。
(2)求解。用归并排序对两个子序列递归地排序。
(3)合并。合并两个已经排好序的子序列以得到排序结果。
真题答案
| 题号 | 答案 |
|---|---|
| 2.1 | B、A |
| 2.2 | A |
| 2.3 | D |
| 2.4 | B |
| 2.5 | A |
| 2.6 | D |
| 3.1 | D |
| 3.2 | C |
| 3.3 | D |
| 3.4 | D |
| 3.5 | A、A |
| 3.6 | B、A |
| 3.7 | A、B |
| 4.1 | B |


感谢您的耐心阅读!来选个表情,或者留个评论吧!